
布隆过滤器和Guava的实现
介绍
布隆过滤器实际上是一个很长的二进制向量和一系列的随机映射函数。可用于检索一个元素是否在一个集合中。
使用场景
- 一个大型的爬虫网络中,判断某一个网址是否被访问过。
- 大数据量的词语(句子)去重。
原理
布隆过滤器的核心实现是一个超大的位数组和几个哈希函数。假设数组的长度为m,哈希函数的个数为k。
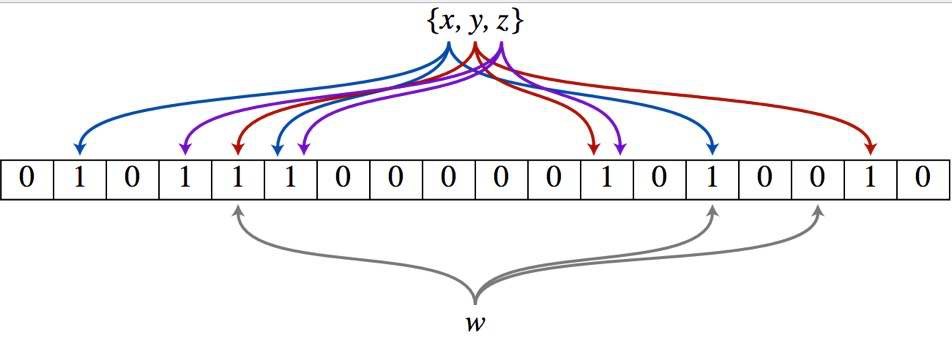
如上图:假设集合里面有x,y,z,通过hash函数计算后的结果为a,b,c,那么w[a],w[b],w[c]都会表标记为1。假设现在有3个hash函数,如图3个不同颜色的线,分别计算出不同的结果,并标记为1。当判断某一个元素是否在一个集合的时候,就通过判断这三个hash的结果,如果都是1,说明该元素在这个集合中。如果有一个为0,说明该元素不在此集合中。因此,这也是存在误判的原因。
总的来说,bloom filter是以极低的的错误去换取空间和时间。
优点
- 有很好的空间和时间效率。
- 不存在漏报的问题,就是说如果元素存在的话,那必定的到的是正确的结果,这个元素确实是存在的。
- 不是用原始数据进行的判断,对于某些敏感的数据也是可以适用的。
缺点
- 误报率随着元素的增加,误报(将不存在的元素判定为存在)也会越严重。
- 不能删除已添加的元素,因为是多个hash函数的结果值对应一个元素。
自己实现一个简单的BloomFilter
public interface BloomFilter<T> {
/**
* 添加一个数据到bloomfilter内
*
* @param element 要添加的元素
*/
void add(T element);
/**
* 判断该过滤器内是否存在元素
*
* @param element 被判断的元素
* @return 是否存在
*/
boolean contains(T element);
}
import java.util.BitSet;
public class SimpleBloomFilter implements BloomFilter<String> {
/**
* 存储的bit容量
*/
private static final int DEFAULT_SIZE = Integer.MAX_VALUE;
/**
* 存储标志位的bits
*/
private BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* 不同hash函数的种子
*/
private static final int[] seeds = new int[]{113, 213, 3111, 397, 611, 532};
/**
* hash函数的数组
*/
private SimpleHash[] hashFunction = new SimpleHash[seeds.length];
public SimpleBloomFilter() {
// 默认初始化 hashFunction
for (int i = 0; i < seeds.length; i++) {
hashFunction[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
@Override
public void add(String element) {
for (SimpleHash function : hashFunction) {
final int hash = function.hash(element);
bits.set(hash, true);
}
}
@Override
public boolean contains(String element) {
for (SimpleHash function : hashFunction) {
if (!bits.get(function.hash(element))) {
return false;
}
}
return true;
}
private static class SimpleHash {
private int cap;
private int seed;
private SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 简单的写一个hash算法
*/
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i) + value.hashCode();
}
// 把值的范围控制在cap内
return (cap - 1) & result;
}
}
}
Guava中的BloomFilter
主要是两个类,com.google.common.hash.BloomFilter和com.google.common.hash.BloomFilterStrategies。
/** The bit set of the BloomFilter (not necessarily power of 2!) */
private final BitArray bits;
/** Number of hashes per element */
private final int numHashFunctions;
/** The funnel to translate Ts to bytes */
private final Funnel<? super T> funnel;
/**
* The strategy we employ to map an element T to {@code numHashFunctions} bit indexes.
*/
private final Strategy strategy;
四个成员变量,BitArray是BloomFilterStrategies中的静态内部类。作用和上面的BitSet类似。有基本的get和set方法,同时提供了一些其他常用的方法。
static final class BitArray {
final long[] data;
long bitCount;
BitArray(long bits) {
this(new long[Ints.checkedCast(LongMath.divide(bits, 64, RoundingMode.CEILING))]);
}
// Used by serialization
BitArray(long[] data) {
checkArgument(data.length > 0, "data length is zero!");
this.data = data;
long bitCount = 0;
for (long value : data) {
bitCount += Long.bitCount(value);
}
this.bitCount = bitCount;
}
/** Returns true if the bit changed value. */
boolean set(long index) {
if (!get(index)) {
data[(int) (index >>> 6)] |= (1L << index);
bitCount++;
return true;
}
return false;
}
boolean get(long index) {
return (data[(int) (index >>> 6)] & (1L << index)) != 0;
}
/** Number of bits */
long bitSize() {
return (long) data.length * Long.SIZE;
}
/** Number of set bits (1s) */
long bitCount() {
return bitCount;
}
BitArray copy() {
return new BitArray(data.clone());
}
/** Combines the two BitArrays using bitwise OR. */
void putAll(BitArray array) {
checkArgument(
data.length == array.data.length,
"BitArrays must be of equal length (%s != %s)",
data.length,
array.data.length);
bitCount = 0;
for (int i = 0; i < data.length; i++) {
data[i] |= array.data[i];
bitCount += Long.bitCount(data[i]);
}
}
@Override
public boolean equals(@Nullable Object o) {
if (o instanceof BitArray) {
BitArray bitArray = (BitArray) o;
return Arrays.equals(data, bitArray.data);
}
return false;
}
@Override
public int hashCode() {
return Arrays.hashCode(data);
}
}
numHashFunctions是表示一个元素对应了几个hash函数,和上面hashFunction.length是一个意思。
strategy是把元素映射为hash值的策略,类似上面的hashFunction。BloomFilter定了了Strategy接口。put方法把numHashFunctions个通过计算后的值放入bitArray中。mightContain返回该过滤器是否可能含有元素T。ordinal就是枚举类的ordinal()。
interface Strategy extends java.io.Serializable {
/**
* Sets {@code numHashFunctions} bits of the given bit array, by hashing a user element.
*
* <p>Returns whether any bits changed as a result of this operation.
*/
<T> boolean put(T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits);
/**
* Queries {@code numHashFunctions} bits of the given bit array, by hashing a user element;
* returns {@code true} if and only if all selected bits are set.
*/
<T> boolean mightContain(
T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits);
/**
* Identifier used to encode this strategy, when marshalled as part of a BloomFilter. Only
* values in the [-128, 127] range are valid for the compact serial form. Non-negative values
* are reserved for enums defined in BloomFilterStrategies; negative values are reserved for any
* custom, stateful strategy we may define (e.g. any kind of strategy that would depend on user
* input).
*/
int ordinal();
}
并在BloomFilterStrategies中给出了两个实现的枚举。
MURMUR128_MITZ_32() {
@Override
public <T> boolean put(
T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits) {
long bitSize = bits.bitSize();
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
boolean bitsChanged = false;
for (int i = 1; i <= numHashFunctions; i++) {
int combinedHash = hash1 + (i * hash2);
// Flip all the bits if it's negative (guaranteed positive number)
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
bitsChanged |= bits.set(combinedHash % bitSize);
}
return bitsChanged;
}
@Override
public <T> boolean mightContain(
T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits) {
long bitSize = bits.bitSize();
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int combinedHash = hash1 + (i * hash2);
// Flip all the bits if it's negative (guaranteed positive number)
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
if (!bits.get(combinedHash % bitSize)) {
return false;
}
}
return true;
}
},
/**
* This strategy uses all 128 bits of {@link Hashing#murmur3_128} when hashing. It looks different
* than the implementation in MURMUR128_MITZ_32 because we're avoiding the multiplication in the
* loop and doing a (much simpler) += hash2. We're also changing the index to a positive number by
* AND'ing with Long.MAX_VALUE instead of flipping the bits.
*/
MURMUR128_MITZ_64() {
@Override
public <T> boolean put(
T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
boolean bitsChanged = false;
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);
combinedHash += hash2;
}
return bitsChanged;
}
@Override
public <T> boolean mightContain(
T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
if (!bits.get((combinedHash & Long.MAX_VALUE) % bitSize)) {
return false;
}
combinedHash += hash2;
}
return true;
}
private /* static */ long lowerEight(byte[] bytes) {
return Longs.fromBytes(
bytes[7], bytes[6], bytes[5], bytes[4], bytes[3], bytes[2], bytes[1], bytes[0]);
}
private /* static */ long upperEight(byte[] bytes) {
return Longs.fromBytes(
bytes[15], bytes[14], bytes[13], bytes[12], bytes[11], bytes[10], bytes[9], bytes[8]);
}
};
Guava就是选取了这两个hash算法中的一个,创建一个BloomFilter可以指定其中的一个算法,具体的算法逻辑可以参看解读BloomFilter算法
使用实例:
private static void bloomFilter() throws Exception {
final BloomFilter<String> dealIdBloomFilter = BloomFilter.create(new Funnel<String>() {
@Override
public void funnel(String from, PrimitiveSink into) {
into.putString(from, Charsets.UTF_8);
}
}, 3000000, 0.0000001d);
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(new File("C:\\Users\\Methol\\Desktop\\jiaokao-word.txt")), "utf-8"));
String line;
int i = 0;
StringBuilder sb = new StringBuilder();
while ((line = br.readLine()) != null) {
if (!dealIdBloomFilter.mightContain(line)) {
dealIdBloomFilter.put(line);
sb.append(line).append("\n");
i++;
}
if (i % 1000 == 0) {
FileUtils.write(new File("C:\\Users\\Methol\\Desktop\\bloomFilterDistinct.txt"),
sb.toString(), Charsets.UTF_8, true);
sb = new StringBuilder();
}
}
FileUtils.write(new File("C:\\Users\\Methol\\Desktop\\bloomFilterDistinct.txt"),
sb.toString(), Charsets.UTF_8, true);
}
扩展
同样对大数据量的内容进行滤重,当时还想到了用spark,不过这个真的有点大炮打小鸟的感觉,用起来代码是非常简单,但是单单就滤重这件事来说,还是BloomFilter好用。
800w行的句子,滤重后有200w,spark的用时比BloomFilter略多。
贴一段spark的代码:
private static void spark() {
System.setProperty("hadoop.home.dir", "D:\\server\\hadoop-common-2.2.0\\");
SparkConf conf = new SparkConf().setAppName("Text String Distinct").setMaster("local").set("spark.executor.memory", "1g");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> textFile = sc.textFile("C:\\Users\\Methol\\Desktop\\jiaokao-word.txt");
final JavaRDD<String> distinct = textFile.distinct();
final long count = distinct.count();
System.out.println(count);
distinct.coalesce(1).saveAsTextFile("C:\\Users\\Methol\\Desktop\\distinct");
}